回溯算法练习题 | 子集问题
LeetCode链接:78. 子集
1.题目描述
给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。
示例 1:
示例 2:
1
2
| 输入:nums = [0,1]
输出:[[0,1],[1,0]]
|
示例 3:
提示:
1 <= nums.length <= 6-10 <= nums[i] <= 10nums 中的所有整数 互不相同
2.题解
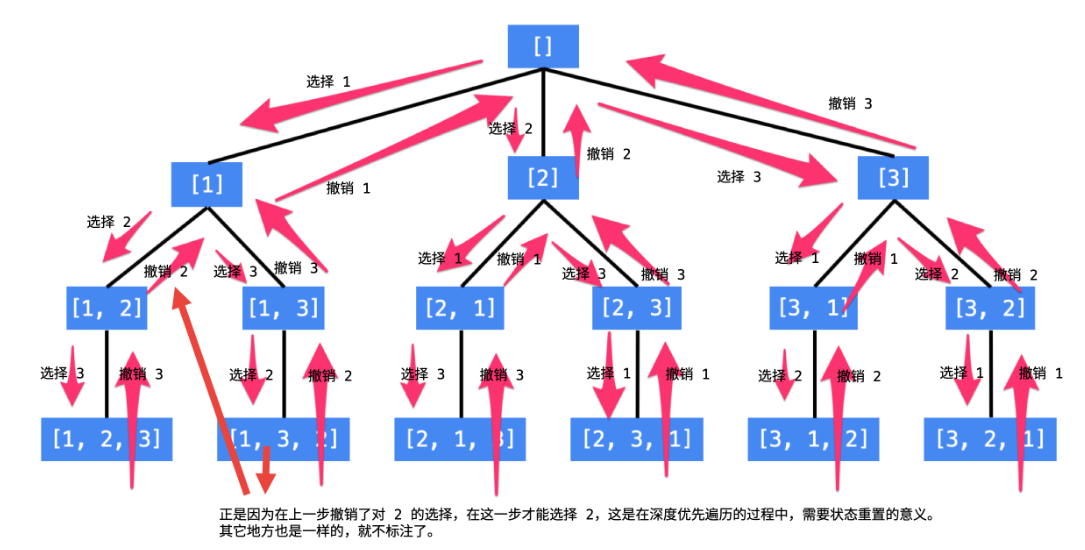
2.1 回溯解法1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| class Solution {
List<List<Integer>> result = new ArrayList<>();
List<Integer> path = new ArrayList<>();
public List<List<Integer>> permute(int[] nums) {
backtracking(nums, new boolean[nums.length]);
return result;
}
public void backtracking(int[] nums, boolean[] used) {
if (path.size() == nums.length) {
result.add(new ArrayList<>(path));
return;
}
for (int i = 0; i < nums.length; i++) {
if (used[i]) continue;
used[i] = true;
path.add(nums[i]);
backtracking(nums, used);
path.remove(path.size() - 1);
used[i] = false;
}
}
}
|
2.2 回溯解法2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| class Solution {
List<List<Integer>> result = new ArrayList<>();
List<Integer> path = new ArrayList<>();
public List<List<Integer>> permute(int[] nums) {
backtracking(nums, new boolean[nums.length]);
return result;
}
public void backtracking(int[] nums, boolean[] used) {
if (path.size() == nums.length) {
result.add(new ArrayList<>(path));
return;
}
for (int i = 0; i < nums.length; i++) {
if (path.contains(nums[i])) continue;
path.add(nums[i]);
backtracking(nums, used);
path.remove(path.size() - 1);
}
}
}
|
1.题目描述
给定一个可包含重复数字的序列 nums ,按任意顺序 返回所有不重复的全排列。
示例 1:
示例 2:
提示:
1 <= nums.length <= 8-10 <= nums[i] <= 10
2.题解
2.1 回溯算法-哈希集合去重
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| class Solution {
List<List<Integer>> result = new ArrayList<>();
List<Integer> path = new ArrayList<>();
public List<List<Integer>> permuteUnique(int[] nums) {
backtracking(nums, new boolean[nums.length]);
return result;
}
public void backtracking(int[] nums, boolean[] used) {
if (path.size() == nums.length) {
result.add(new ArrayList<>(path));
return;
}
Set<Integer> set = new HashSet<>();
for (int i = 0; i < nums.length; i++) {
if (used[i] || set.contains(nums[i])) continue;
set.add(nums[i]);
used[i] = true;
path.add(nums[i]);
backtracking(nums, used);
path.remove(path.size() - 1);
used[i] = false;
}
}
}
|
2.2 回溯算法-哈希数组去重
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| class Solution {
List<List<Integer>> result = new ArrayList<>();
List<Integer> path = new ArrayList<>();
public List<List<Integer>> permuteUnique(int[] nums) {
boolean[] used = new boolean[nums.length];
backtracking(nums, used);
return result;
}
public void backtracking(int[] nums, boolean[] used) {
if (path.size() == nums.length) {
result.add(new ArrayList<>(path));
return;
}
int[] hash = new int[21];
for (int i = 0; i < nums.length; i++) {
if (used[i] || hash[nums[i] + 10] == 1) continue;
used[i] = true;
hash[nums[i] + 10] = 1;
path.add(nums[i]);
backtracking(nums, used);
path.remove(path.size() - 1);
used[i] = false;
}
}
}
|
2.3 回溯算法-排序去重
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| class Solution {
List<List<Integer>> result = new ArrayList<>();
List<Integer> path = new ArrayList<>();
public List<List<Integer>> permuteUnique(int[] nums) {
Arrays.sort(nums);
backtracking(nums, new boolean[nums.length]);
return result;
}
public void backtracking(int[] nums, boolean[] used) {
if (path.size() == nums.length) {
result.add(new ArrayList<>(path));
return;
}
for (int i = 0; i < nums.length; i++) {
if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == false) continue;
if (used[i] == false) {
used[i] = true;
path.add(nums[i]);
backtracking(nums, used);
path.remove(path.size() - 1);
used[i] = false;
}
}
}
}
|
1
2
3
| if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == false) {
continue;
}
|
- **如果改成
used[i - 1] == true, 也是正确的!**,去重代码如下:
1
2
3
| if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == true) {
continue;
}
|
这是为什么呢,就是上面我刚说的,如果要对树层中前一位去重,就用used[i - 1] == false,如果要对树枝前一位去重用used[i - 1] == true。
对于排列问题,树层上去重和树枝上去重,都是可以的,但是树层上去重效率更高!
这么说是不是有点抽象?
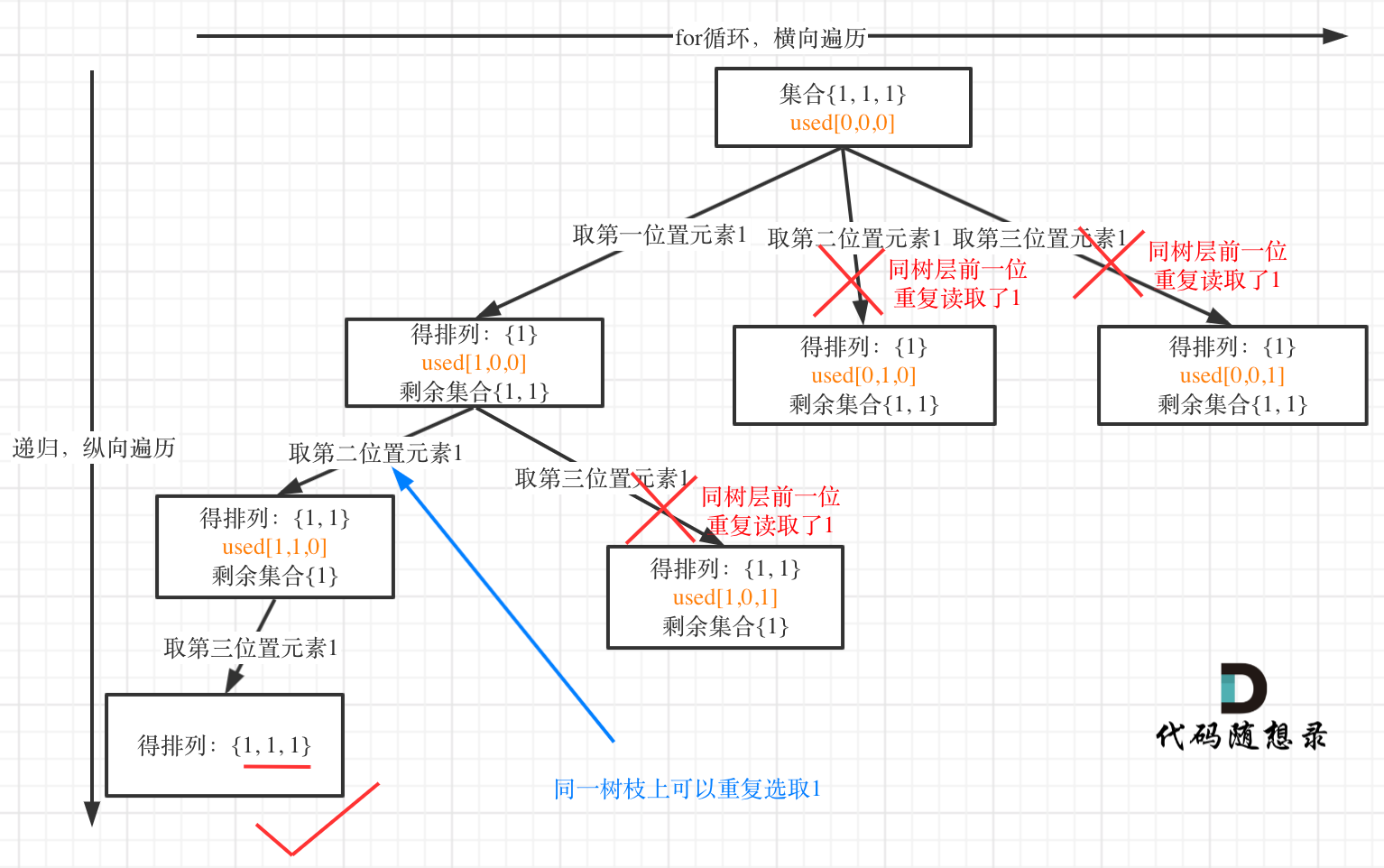
来来来,我就用输入: [1,1,1] 来举一个例子。
树层上去重(used[i - 1] == false),的树形结构如下:
树枝上去重(used[i - 1] == true)的树型结构如下:
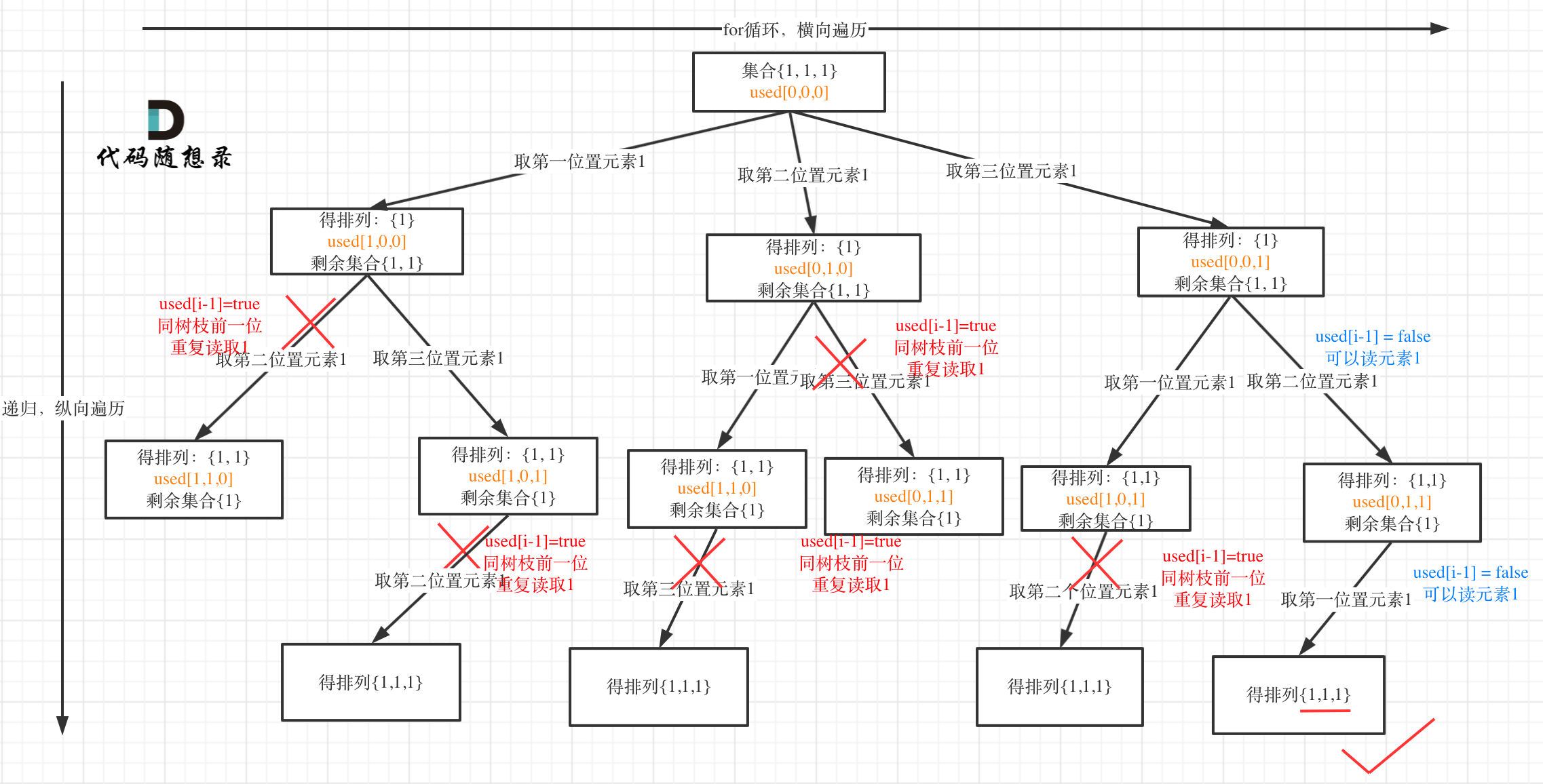
大家应该很清晰的看到,树层上对前一位去重非常彻底,效率很高,树枝上对前一位去重虽然最后可以得到答案,但是做了很多无用搜索